OGsiji_portfolio
Data Science and Analysis Portfolio
Project 1: Exploratory Data Analysis(EDA) of Energy Data: Project Overview
- The major focus of this project was to use EDA to extract meaning/information from data using plots and report important insights about data
- The data fuel quality data from Fedral Energy Regulation Commission which is provided by the United States Energy Information Administration.
- This part is more about data analysis and fuel usage intelligence.
- I also gave interesting insights based on my analysis
-
I suggested data preprocessing, feauture selection and Feauture Engineering options to Apply our Machine Learning algorithims succesfully.

Project 2: Exploratory Data Analysis(EDA) of MPG Data Set : Project Overview
- This part consists of summary statistics of data but the major focus will be on EDA where we extract meaning/information
- This will be done using plots to report important insights about the data.
- This part is more about data analysis and business intelligence(BI).
- The data we are using for EDA is the auto mpg dataset taken from UCI repository.
- I also gave interesting insights based on my analysis
- I suggested data preprocessing, feauture selection and Feauture Engineering options to Apply our Machine Learning algorithims succesfully.
-
In the other parts I plan exploring Statitical Analysis and Predictive Modelling

Project 3: Data-cleaning-challenge-handling-missing-values : Project Overview
- This part contains the cleaning of an nfl play data set
- I got this data set from kaggle
- I performed different filling methods based on the size and the number of the missing values
- I also drop the missing values and used different filling techniques for them
-
I justified the various filling methods by testing the data-set

Project 3: Machine Learning (Simple Linear Regression for Stock Prices Prediction) : Project Overview
- I have always wondered how I could predict stock prices from simple feautures as adjusted Close and High Level Price
- I got this data Set from the quandl data set which is always updated
- I performed a simple linear regression to predict the stock prices based on data sets gotten from weeks before
- I also performed a visualization technique to show the increase on the prices based on Time-Series Data Analysis of the Feautures.
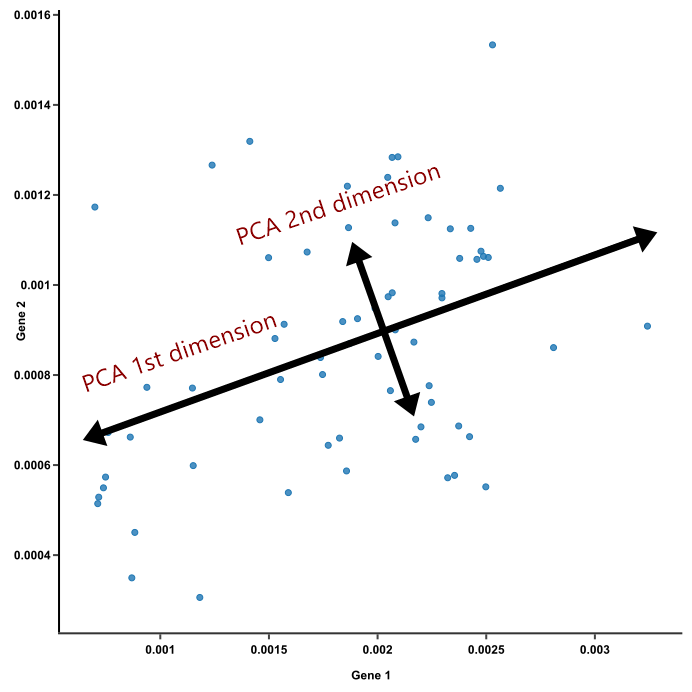
Project 4: PCA (Principal Component Analysis on Iris-Data Set) : Project Overview
- Principal Component Analysis is one of the best ways to get meaningful and effective predictions on our Data Sets
- The data we are using for PCA is taken from UCI repository.
- I performed a PCA on an Iris Flower Data Set and I got two dimensions which have the highest Variance
- I also applied a simple Classification Algorithim on it
Project 5: Machine Learning (Simple Logistic Regression on Titanic Data Set) : Project Overview
- Titanic Data Set is one of the most Sedomly used data Set by Data Scientist
- The Titanic data we are using for Simple Logistic Regression is taken from Kaggle
- I applied Logistic Regression which helped me predict those who survived the Ship Wreck based on my Feautures
- I performed the Loading of libraries and datasets, Exploratory Data analysis,Feature Engineering,Training Model and predictions
-
I also got very good accuracy and score based on my data cleaning approach.

Project 6: Machine Learning (Classification Algorithim Performance on Advertisement Data Set) : Project Overview
- This is one of the Most passionate Project I worked on
- I applied all the machine learning classification algorithim on the Advertisment Data Set
- The Advertisement data we are using for classification algorithim is taken from UCI repository.
- I tuned my parameters appropraitely performing error analysis on each algorithim to check the algorithim that will give the best score
-
I realised that using Bagging Ensemble Methods (Random Forest Classifier gave me the best Scores)

Project 7: Machine Learning (Tunisian Fraud Detection Challenge using Machine Learning Regression Model) : Project Overview
- Tax fraud is the intentional act of lying on a tax return form with the intent to lower one’s tax liability.
- The objective of the challenge is to detect tax fraud.
- Using historical data, I used supervised machine learning technique that detects potential fraudulent taxpayers
- This will increase the operational efficiency of the tax supervision process.
- The data we are using for EDA is the Tunisia Data dataset taken from Zindi.
- I used Boosting Ensemble Methods to get better Scores

Project 8: Machine Learning (Urban Air Pollution Prediction Hackathon using Machine Learning Regression Model) : Project Overview
- Finding ways to track air quality and how it is changing, even in places without ground-based sensors.
- This information will be especially useful in the face of the current crisis, since poor air quality makes a respiratory disease like COVID-19 more dangerous.
- I collected weather data and daily observations from the Sentinel 5P satellite tracking various pollutants in the atmosphere via Zindi.
- My goal is to use this information to predict PM2.5 particulate matter concentration (a common measure of air quality that normally requires ground-based sensors to measure) every day for each city.
- The data covers the last three months, spanning hundreds of cities across the globe.
- I used Boosting Ensemble Methods to get better Scores
